
-
这是“神经工程管理”第11篇推送
-
内容来源:王卓琳
-
本期编辑:薛朋东
-
校 对: 邢孟林
-
审 核:付汉良
-
仅用于学术交流,原文版权归原作者和原发刊所有


本文是针对论文《使用眼动跟踪数据实现个性化安全培训的自动化和规模化》(Automating and scaling personalized safety training using eye-tracking data)的一篇论文解析。该论文于2018年发表于《Automation in Construction》。论文作者包括Idris Jeelani , Kevin Han, Alex Albert。
 关键词:危险识别;施工安全;3D-重建;眼动追踪;计算机视觉;个性化培训
关键词:危险识别;施工安全;3D-重建;眼动追踪;计算机视觉;个性化培训
研究发现,工人对建筑危险的识别能力不佳导致建筑业生命和经济损失十分严重,而通过提升工人的危险识别能力来改善安全管理则是受到证实的;Jeelani团队和Dzeng团队发现工人的观察模式与他们的危险识别能力之间存在显著的相关性,危险识别本质上就是以危险为对象的多目标视觉搜索过程。眼动跟踪技术是分析和检测视觉搜索最有效的工具之一,计算机视觉和可穿戴眼动追踪技术的进步使捕捉和分析工人的实际动态成为可能,为实验提供了技术保障。
1.实验设计
该实验分为预处理和测试两阶段完成,并在测试阶段完成后手动计算数据,将手动计算的数据与系统所得数据进行比较,验证实验结果及所开发系统的准确性。该实验选取六名被试佩戴眼动追踪眼镜[一种可穿戴的眼动追踪设备,Tobii Glasses 2 ,具有高清晰度的摄像机(见图1)用于记录实验所需视频]在两个性质不同的实验地点走动进行测试,选取性质不同实验地点的目的是验证系统所提供的不同视觉环境。

图1 . Tobii Glasses 2的部件
2.实验步骤
1)用特征确定匹配图像集,并据此生成场景的稀疏3D点云
①获取初始集并校准摄像机,防止镜头失真;确定摄像机在场景中的位置;并通过眼动追踪眼镜的摄像头拍摄到的多轨迹场景视频(多轨迹拍摄是为了保证从不同角度和距离捕捉对象)提取图像帧,用于标注和重建3D点云的初始集。校正摄像机:本研究使用典型的校准板,尺寸为1330mm×931mm和133mm×133mm,校准结果总结在表1中。其中平均重投影误差(MRE)是在图像中检测到的关键点与使用估计的摄像机参数在同一图像上重新投影的对应点之间的平均距离。获取初始集:本研究中视频每秒25帧,分辨率200万像素。A地点的实验视频长度为102s,提取了2512帧;B地点是从183秒的实验视频中提取4562帧。

②SIFT特征提取与三维重建。利用尺度不变特征变换(SIFT)算法从这些图像中检测和提取特征用于在初始集合中的图像之间找到对应的匹配,并将这些匹配运用离线算法(SfM)生成场景的稀疏3D点云。相应的特征匹配也进行存储,在下一步骤(即测试阶段)中用于计算单应矩阵。本研究中采用VisualSFM进行特征检测、匹配和三维重建。使用NVIDIA 1080GTX GPU进行成对匹配,并存储对应关系以供下一步使用。
在这一步,安全管理人员识别出应重点关注的危险,并将危险信息添加到三维模型中。首先,在初始图像集上用由Xmin、Ymin、Xmax和Ymax参数化了的边界框将这些危险标注为AOIs,标注过程中每个危险至少需要一个手动标注的图像(帧)。手动标注后,可以利用仿射变换计算机视觉算法自动计算该危险在其余图像(帧)中边界框的位置,并根据相应匹配点,获得两幅图像之间的单应矩阵H:xi ’ =Hxi;其中xi = [xiyiwi]T和xi’=[xi’yi’wi’]T是通过两幅图像之间的成对特征匹配得到的点对应。
如下图所示,H和[x;y]的点积将得到图B中的对应点[x’;y’]。因此,可以计算图B的所有边界框参数(Xmin、Ymin、Xmax和Ymax)。使用这种方法,只需要为几个关键帧手动绘制边界框,就可以使用H矩阵为所有相邻图像计算边界框。
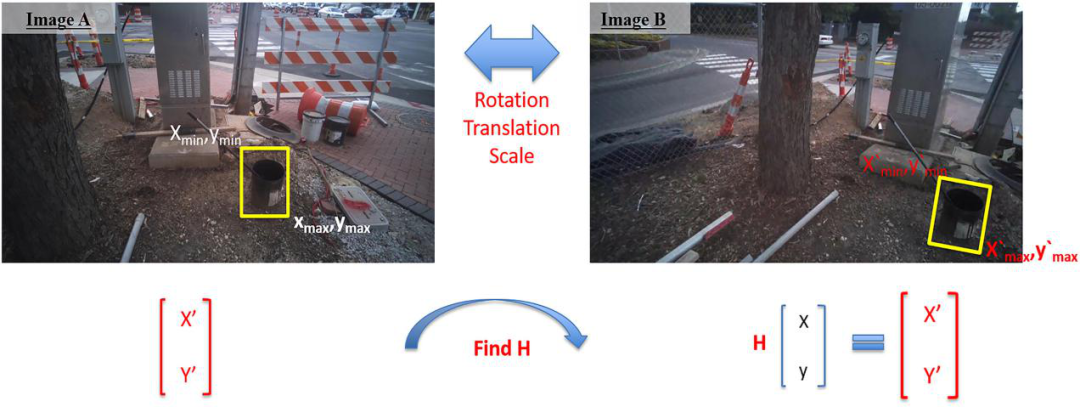
图2.使用H矩阵进行边界框计算
本研究中,由五名具有行业经验的专家预先确定两个建筑地点的危险,两名研究人员分别在A和B地点的50张和75张图像上对预先确定的危险进行手动标注。A点选择了5种危险,B点选择了4种危险。危险如下图所示,危险的具体情况在表2中列出。这里选择的AOI仅用于演示目的,显示如何计算不同的指标。在实际实施中,如果我们想分析这些领域的注意力分布,可能会有几个AOI,其中也可能包括非危险因素。

图3.a、b地点的预定危险
表2.危险说明

危险用矩形边界框进行标注。在初始图像集中使用上述方法计算边界框,并将其存储在4M×N数组中,其中N=图像数,M=危险数。如下表3显示了该数组的一部分。对于每个边界框,有四列存储Xmin、Ymin、Xmax和Ymax(‘—’表示AOI在该帧中不可见)。
表3.由边界框参数定义的AOI

这一阶段的目的是收集被试在建筑工地周围移动时的眼动追踪数据,并使用上一阶段开发的模型以规则的时间间隔定位被试及其注视位置。 随后,我们检查局部注视位置是否在预定义的AOI内,用来计算被试在每个AOI上注视的次数和时间。这些数据最终用于确定被试在建筑工地上的注意力分布,并计算工人对每个AOI的探测能力评分。测试阶段包括以下步骤:
被试佩戴眼动追踪眼镜在工地上完成日常工作,设备配备了一个安装在前面的高清晰度场景摄像头,它可以捕捉第一人称视图,即FPV(使用同一摄像机获取预处理阶段中讨论的实验视频)。从录制的视频中提取图像帧作为被试的测试集图像,用于定位工人。同时设备还可以通过角膜反射技术来捕捉眼睛注视的中心和方向,获取每一帧的注视位置,计算工人在实验过程中的注视位置,以此来绘制他们的注意力分布图。在本研究中,三名被试佩戴Tobii Glasses 2(采样率为100 Hz,视角为水平82°,垂直52°,视野90°)捕捉眼球运动,被试在每个建筑工地内移动,下表为收集的参与者数据:
表4.参与者数据

数据存储通过HDMI连接到眼镜的记录单元中,原始数据以JavaScript Object Notation(JSON)文件(见下图)输出,其中包含瞳孔中心(PC)、瞳孔直径(PD)、2D(GP)和3D(GP3)中注视位置和注视方向(Gd)的数据行。每个JSON行由一个允许我们同步数据的时间戳(TS)和一个标志变量s组成,如果记录过程中出现任何错误,标志变量s将标记为(即s=1),在这种情况下,该时间戳的相应行被拒绝。

图4.从眼动跟踪导出的原始数据中摘录
利用在预处理阶段定义的AOI位置来定位工人及其注视位置,并绘制被试的视觉注意力分布图,计算工人对不同危险的探测能力评分,下图概述了数据处理步骤:
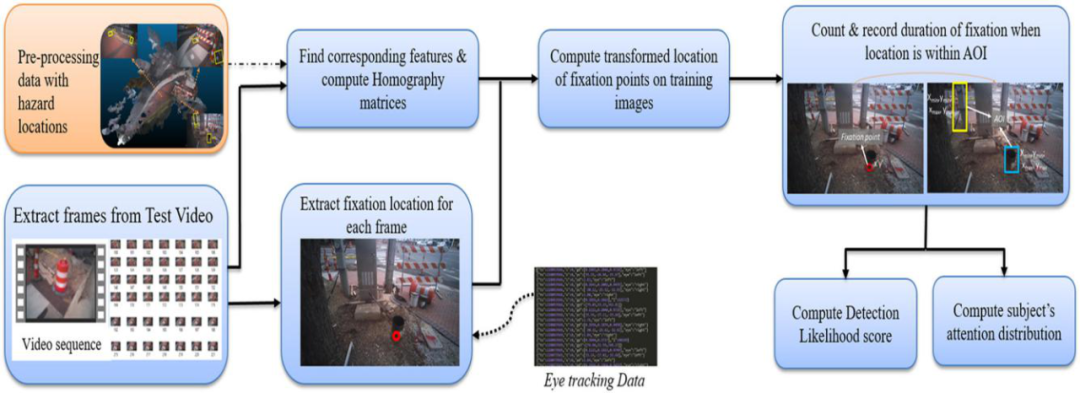
图5.数据处理用于计算工人对于危险的探测能力评分和注意力分布情况
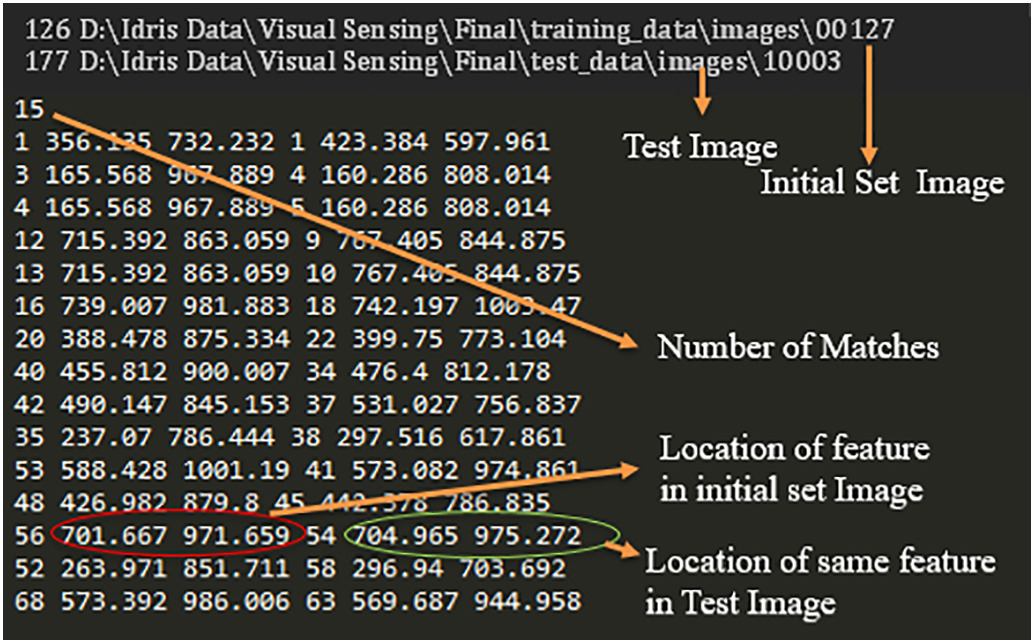
①定位被试位置。将测试图像添加到(在预处理阶段获得的)3D点云中,提取测试图像的SIFT特征,并将其与初始集的特征进行匹配,为每个测试图像找到初始图像集中与其具有最大匹配特征的对应图像。由于我们有一个连续的测试图像流,如果视频以每秒25帧(FPS)的速度记录,我们可以每0.04秒获得一次工人的位置。因此我们可以通过匹配,根据初始集图像中已知摄像机的位置推测拍摄测试图像时被测对象的大致位置,以下数组按顺序计算可用于定位工人。
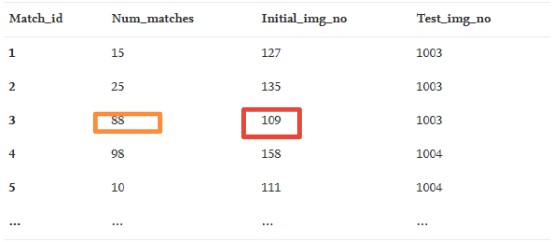
匹配:N×4数组容纳每个匹配项的匹配特征数,其中N是初始集合中图像数与测试图像数的乘积。每个匹配项都有一个唯一的id。如表5所示,该数组包括匹配id、初始设置的图像编号、测试图像编号以及两者之间的匹配特征数。
匹配点:“matched_pt”是一个三维数组,用于容纳每个匹配的匹配要素的坐标。对于初始设置图像和测试图像,每个匹配(用match_id索引)的对应点(匹配特征)的坐标分别存储为x1,y1;x2,y2,这些点用于计算匹配图像之间的单应矩阵H。
最佳匹配:对于每个测试图像,从初始集获得具有最多特征匹配数的对应图像。 这是通过从匹配数组中为该测试图像选择具有最大匹配数的行来完成的。例如,在下表中,测试图像#10003的最佳匹配是具有88个匹配点的初始图像#109。这些最佳匹配存储在名为“best_matches”的M×3数组中,其中M是测试图像的数量。
表5.摘录自“匹配”数组
②获得每一帧的注视位置。眼动追踪数据流包含工人每0.01秒的注视位置,使用时间戳,提取每个测试图像对应的注视位置,并将其转换到初始集中定义的AOI坐标系中,定位被试注视位置(例如,凝视位置(x,y)t是参与者在时间t注视的位置)。
③转换注视位置。因为测试集与初始图像集之间存在着比例、旋转的差异,因此,我们需要计算数据处理阶段第(1)步中所获得的每个匹配的单应矩阵(H),并将测试图像中的注视位置(x,y)转换为初始图像集上的对应点(x’,y’),然后检查(x‘,y’)是否在边界框内(见下图)。

图6.定位与AOIs相关的注视位置
④获得可以预先识别危险的观察模式。得到转换点(x’,y’)后,看是否满足以下条件,如果满足条件,则意味着注视位置在初始集用边界框定义的AOI范围内。例如,在图6中,蓝色AOI的边界框参数满足该条件,表明注视点(x’,y’)在蓝色AOI内。(由于视觉搜索过程中的平均注视持续时间约为180~275毫秒,因此这些条件必须在至少六个连续帧内保持为真,才能算作注视(在25FPS,6帧~240ms)。在这种情况下,对特定的AOI进行注视计数,并通过计算满足条件的第一个时间戳与失败前的最后一个时间戳之间的差异来测量注视的持续时间)X’>XminANDX’ <XmaxANDY’ >YminANDY’<Ymax
本研究中,利用VisualSFM从测试图像中提取SIFT特征,使用Nvidia 1080 GPU的处理次数如表6所示,
利用这些特征,找到每个测试图像的最佳匹配。下图显示了来自Visual SFM的文本文件摘录以及本研究中使用的信息类型,对此文本文件进行处理,以制定数据处理阶段第1)步中描述的匹配、匹配点和最佳匹配,以定位被试。
表6.进行特征提取和匹配的处理时间

解析JSON文件,并提取包含gp的数据行,“gp”是图像平面上投射视线的点。使用时间戳,数据与实验视频的帧速率同步,提取每个测试图像(实验视频的每个帧)的注视位置。
3)数据分析与反馈生成
①个性化反馈。通过计算注视次数和注视持续时间,用六种指标定义一个人的观察模式。
a)停留时间:每个AOI的停留时间是每个参与者在该AOI上的注视时间总和,不同AOI上的不同停留时间表示了参与者的视觉注意力在场景中是如何分布的。第j个AOI的停留时间计算如下:
 (1)
(1)
其中DTJ是第j个AOI的停留时间,E和S是第j个AOI的第i个注视(fi)的开始时间和结束时间
b)注视计数(FC):它表示参与者投入视觉注意力的不同对象/区域的数量,注视的次数表示对象/区域的重要性或“可注意性”
C)注视时间(FT):注视时间是每个参与者在注视不同对象或区域时所花费的时间,它表示参与者在给定场景中所给予的视觉注意力的量,计算方式为:
 (2)
(2)
其中;E和S是第i个注视(fi)的结束时间和开始时间。
d)平均注视持续时间(MFD):它是所有注视持续时间的总和除以注视次数,这个指标表示参与者专注于单个对象所花费的时间,计算方式为:
 (3)
(3)
e)视觉注意力指数(VAI):它表示从场景中获取信息(注视物体)所花费的时间与扫视所花费时间的比例。由于在扫视过程中没有处理有价值的信息,较小的比例表明参与者花更多的时间搜索,而花更少的时间处理和理解目标.视觉注意力指数(VAI)为注视时间与实验持续时间的比率:
 (4)
(4)
f)达标率:全目标注视时间(ROAFT):它是在AOI范围内注视持续时间的总和,除以场景(扫视区域或AOG)中所有注视的总持续时间。这个指标用于表示危险的注意力相对于用于场景的总注意力量的比较,被计算为:
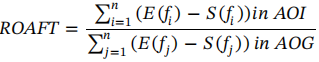 (公式5)
(公式5)
其中;E和S分别是分子和分母中AOI中的第i个注视(fi)和AOG中的第j个注视的结束时间和开始时间;i和j分别是AOI和整个场景(AOG)中的注视次数。
下表记录了本研究中每个参与者的指标计算结果,不同参与者的各项指标数值不同,表示其对于危险的识别能力不同。
表7.基于系统计算的视觉搜索指标

②危险探测能力评分
危险探测能力评分表示该危险所吸引到的注意力大小,由此反映该危险被检测到的可能性大小。使用公式(6)计算危险探测能力评分,分数越高,表示在工作区域检测到该危险的机会就越大。
 (公式6)
(公式6)
其中Sj=第j个危险的危险探测能力评分;Dij表示参与者i在危险j的停留时间;Ti =参与者i的实验持续时间,n=参与者总数;j=危险的数量
本研究比较了几种不同危险引起的视觉注意力分布,结果如表8所示,由图可得A地点的化学桶Ha4被三名参与者注视了17次,总停留时间为4521ms;同样B地点的叉车Hb3吸引的注意力最多,表示这两种安全隐患更有可能被参与者识别。而A地点的电缆Ha2平均吸引的注意力不到搜索持续时间的0.04 %;B地点的压缩气瓶Hb1吸引的注意力最少,表示这两种危险极有可能被工人错过。

1)通过系统计算获得的视觉注意力(即受试者的注意力)分布情况的准确性
由于所有的指标都是从注视的次数和平均注视持续时间得出的,为了验证系统,将系统计算的停留时间与手动计算的AOI停留时间进行比较。
 (7)
(7)
其中,Dij是受试者i在危险j的停留时间(以毫秒为单位);FCij是受试者i在危险j的注视计数=连续6帧的注视在Hj内集合的数目;MFDI是受试者i的平均注视持续时间(以毫秒为单位),平均注视时间是由Tobii’s API导出的原始数据获得的。
手动计算的停留时间与从系统获得的停留时间进行比较(如图8所示)。偏差范围为91ms至203ms(6帧为一次注视,每帧40ms)该偏差结果在合理范围内,两者计算结果基本吻合。
表9.系统计算的停留时间

表10.手动计算在AOIs上停留的时间

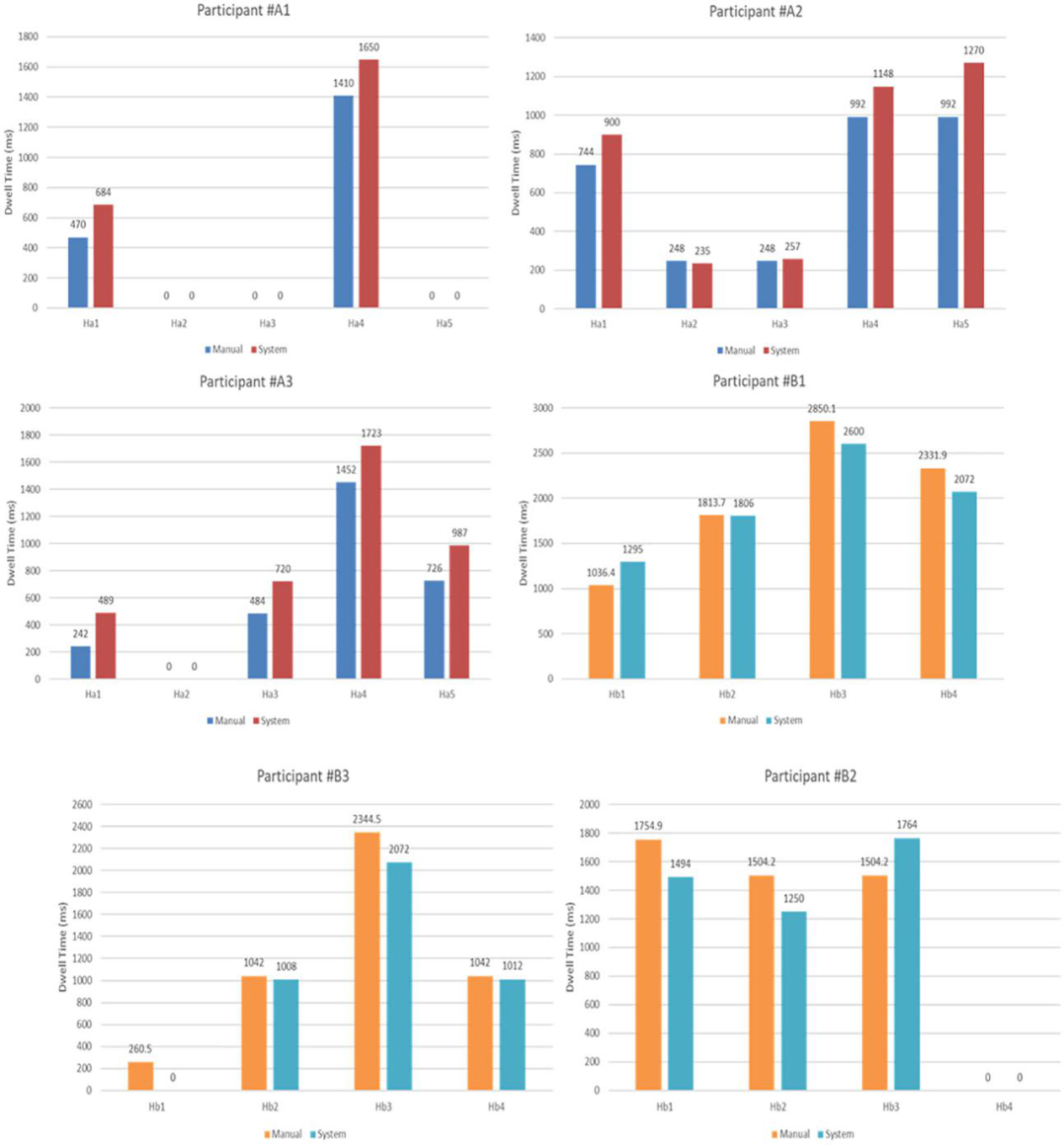
图8.停留时间系统计算与手动计算的比
2)危险探测能力评分在危险检测方面的适用性
为了验证危险探测能力评分的准确性,参与者被要求在实验结束后报告他们在测试现场识别到的危险,采用实验后访谈法计算每个危险的实际探测能力分数,并将其与系统计算获得的危险探测能力评分进行比较。每个危险的实际探测能力评分(Ri)被计算为:
 (公式8)
(公式8)

图9.危险探测评分的系统与手动比较
上图显示了从系统获得的危险探测能力评分和使用公式手动计算的分数进行比较的结果,从图中可以看出,危险探测能力评分的变化与该危险是否能被工人更多次识别到高度相关。
2.计算机视觉技术的使用有助于自动分析眼动追踪数据,为实验提供了更大的样本量,有助于我们了解注意力分布的一般规律,这些信息可用于设计有效的安全措施和培训。研究发现较多危险的工人和发现较少危险的工人视觉注意力分布的不同,这有助于我们理解什么是“良好的危险搜索模式”,从而有助于设计培训策略,帮助工人提高他们的危险识别能力。
1. 试验地点较小导致试验时间比实际工作时间短
2. 测试地点较小限制了样本量的大小
3. 配对匹配的处理时间较长。尽管使用了GPU,但测试地点A和B的配对匹配处理时间仍然超过20小时和45小时。
经过手动计算和系统得出的数据对比验证得出结论:该系统根据眼动追踪数据绘制工人的注意力分布图为工人提供个性化的培训反馈;该系统还可以生成数据来计算工人对不同危险的探测能力评分,这些评分可以帮助我们提前采取预防措施更好的保障工人安全。

引用:
Jeelani I , Han K , Albert A . Automating and scaling personalized safety training using eye-tracking data[J]. Automation in Construction, 2018, 93(SEP.):63-77.





本篇文章来源于微信公众号:神经工程管理